What technologies and methods enable the access and analysis of sensitive data using AI/ML, while preserving data privacy and avoiding centralization? That’s the challenge federated data and data visitation technologies aim to solve. But are they the same thing? Not quite. This post will break down the key differences, explore their respective applications, and provide concrete examples to illuminate these powerful data strategies.
What is Federated Data?
Federated data refers to a data management approach where multiple independent data sources remain decentralized but can be queried and analyzed as if they were a single, unified system. Instead of centralizing data in one location, federated data systems allow access to data stored across different institutions or platforms while maintaining local control over each dataset.
What is Data Visitation?
Data visitation, in contrast, takes a more targeted and temporary approach to data access. Imagine sending a “visitor” to the data, rather than bringing the data to a central location or querying it remotely. In practice, this means executing code or algorithms directly within the environment where the data resides. The “visitor,” essentially a computational process, travels to the data, performs the necessary analysis, and returns only the results, not the raw data itself. This approach is especially valuable when dealing with highly sensitive or large datasets where transferring the data would pose security risks or be computationally expensive. Data visitation prioritizes data locality, minimizes data movement, and enhances privacy by keeping raw data within its original secure environment.
Comparison: Federated Data Systems vs. Data Visitation Technology
| Feature | Federated Data Systems | Data Visitation Technology |
| Data Storage | Data remains distributed across multiple sites, but typically follows a unified structure dictated by a central authority or design. | Data remains at its source, where external algorithms with varying purposes can visit and process it throughout the research process. |
| Implementation Model | Federated technology is often implemented top-down, requiring a predefined data & analysis model for the distributed system. | Data visitation is generally implemented in a bottom-up fashion, where the technology is designed to accommodate diverse data use cases. |
| Data Movement | Queries retrieve data on demand, sometimes requesting relevant data be moved to a centralized system for analysis. | Data does not move; only computational tasks travel to the data source with results (e.g. metadata, a prediction model) sent to a central location. |
| Access Model | Users can query multiple sources as if they were one, with access control policies in place. | Users submit algorithms to be executed at remote data locations, receiving only processed outputs. |
| Security & Privacy | Sensitive data stays within institutional boundaries, but query results may reveal patterns. | Higher security since raw data never leaves its location, reducing exposure risk. |
| Use Cases | Common in research, enterprise, and government for aggregating insights across datasets. | Used in highly sensitive environments like genomics, healthcare, and finance, where strict privacy is required. |
| Challenges | Query performance can be slower due to the distributed nature; requires harmonization of schemas. | Computational constraints at the data source; requires trust in the remote algorithm execution. |
| Scalability | Can be scaled with proper indexing, caching, and distributed query optimization. | Limited by the computational resources available at each data location. |
| Examples | – Google BigQuery (federated queries) – OHDSI (Observational Health Data Sciences and Informatics) – Federated learning models in AI (e.g., Google’s Federated Learning) – Gaia-X (European federated data infrastructure) – DataSHIELD (privacy-preserving federated data analysis) – TriNetX/i2b2 (clinical research network) – European-Canadian Cancer Network (EUCANCan, cross-border cancer research collaboration) – Swarm Learning networks (decentralized AI training) – GA4GH Beacon Network (secure genomic data queries) | – UK Biobank (researchers submit algorithms for analysis) – Secure multiparty computation (used in finance & healthcare) – Personal Health Train (health data analysis without moving data) – FAIRlyz (data visitation for research & secure data analysis) |
A Federated Data Example: OHDSI Federated Data Network Model
This article describes the OHDSI Federated Data Network Model. Below is a graph redrawn from the figure in the article.

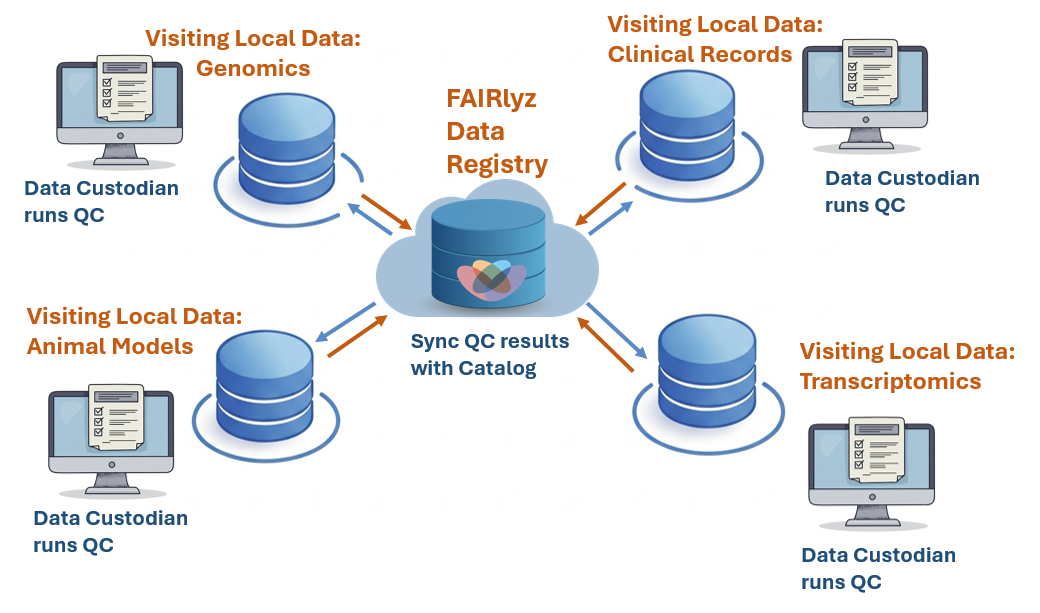
A Data Visitation Example: FAIRlyz Data Registry with Quality Control
FAIRlyz is a Data Registry offering secure data visitation for AI-aided quality control of sensitive data.

Conclusion
As we have explored, federated data systems excel in scenarios requiring broad data aggregation and analysis across multiple sources, such as in large-scale research projects or enterprise-wide data initiatives. Data visitation technology proves invaluable in situations where support for different use cases, data sensitivity and privacy are paramount, such as in healthcare, genomics, and finance. Ultimately, both approaches play crucial roles in enabling responsible and effective data utilization, including AI access, within today’s complex data landscape.
The report titled “Geographies of Trust: AI, Biomedicine, and the Next Era of Federated and Visiting Data Models” provides a more detailed discussion of this topic and is available at: https://doi.org/10.5281/zenodo.16929065.
Acknowledgement
This blog post was published as part of the DV4RDA project. The DV4RDA project has received funding through RDA TIGER from the European Union’s Horizon Europe framework programme under grant agreement No. 101094406. Views and opinions expressed are however those of the authors only and do not necessarily reflect those of the European Union or institutions represented here. Neither the European Union nor the institutions can be held responsible for them.
