Electronic Health Records were meant to be the backbone of modern healthcare and AI clinical prediction system. Instead, the 2025 research landscape paints a sobering picture. EHR data is incomplete, inconsistent, and often wrong at a scale that threatens clinical research, AI development, and even day‑to‑day patient care.
Across multiple new studies, a consistent theme emerges about a future of healthcare build on a shaky data foundation of unvalidated EHR Data. Part 1 present 3 studies from 2025, and Part 2 presents 2 more studies describing the pitfalls of traditional data pipelines. A new class of data‑visiting quality‑control tools, such as FAIRlyz, may offer the first realistic path to fixing EHR data before it becomes a downstream disaster.
The discussion starts with several 2025 articles and papers:
Study 1. Up to 30% of EHR Data Is Invalid
Lotspeich et al. (2025) report that 30% of key EHR fields contain invalid or unusable values. The paper focuses on the Allostatic Load Index (ALI), a 10-component measure used to quantify “whole-person health.” While Electronic Health Records (EHRs) offer a massive secondary data source for calculating this index, the authors identify two critical data quality hurdles:
- Missingness: Many patients lack the full suite of lab tests or vitals needed for the index because EHR data is collected for clinical care, not research.
- Inaccuracy: Automated extraction from EHRs (e.g., via a “data lake”) can contain errors that standard cleaning scripts miss.
The Solution: The authors propose a “two-phase” framework to improve data quality:
- Enriched Validation Protocol: If a value (like BMI or a lab result) was missing in the structured data, reviewers reviewed the patient’s unstructured notes or related diagnoses to recover that information.
- Targeted Sampling: Since manual chart review is expensive, the researchers used a statistical strategy called “residual sampling.” They identified which specific patient records would be most “informative” to validate.
Study 2. Missing Data Is Widespread and Non‑Random
Digitale et al. (2025) show that 18% of EHR data is missing. The authors highlight a critical problem: many traditional statistical methods for fixing missing data (like Multiple Imputation) are designed for research studies where you have all the data at once. These methods often fail when applied to clinical prediction models that need to work in real-time at the bedside, where data is arriving sequentially and decisions must be made immediately, such as in a Pediatric Intensive Care Unit setting.
The Solution: Simple is often better for real-time quality: Surprisingly, the researchers found that Last Observation Carried Forward (LOCF), a simple method that “visits” the most recent known data point often outperformed complex mathematical models.
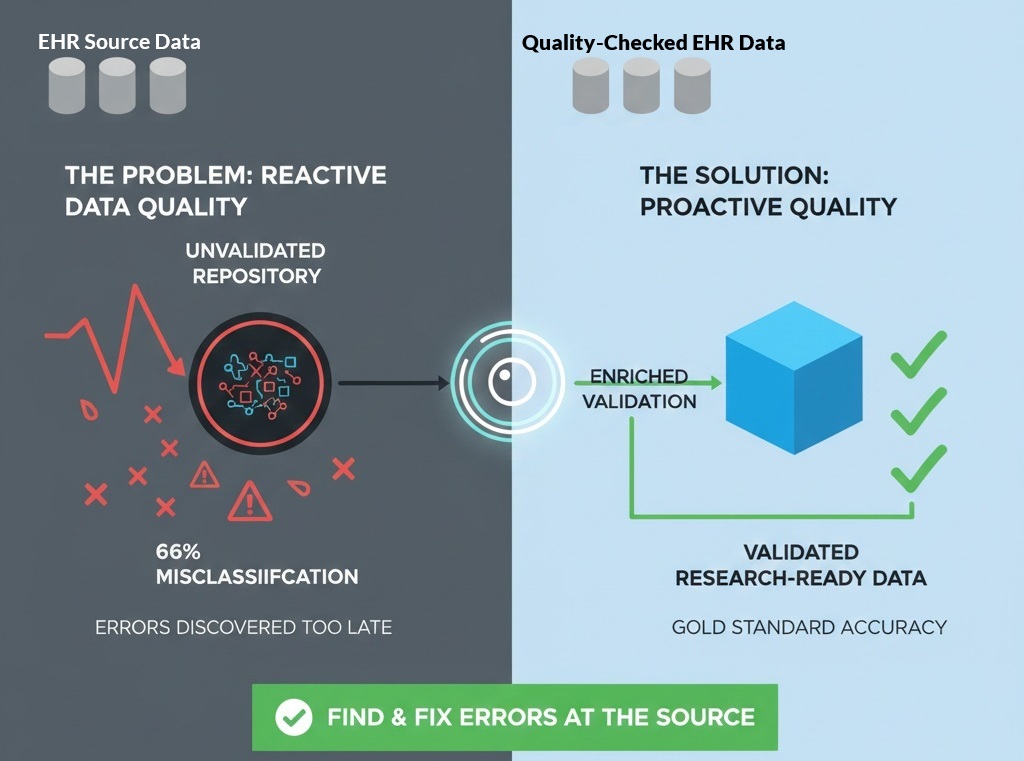
Study 3. Billing Codes Misclassify Up to 66% of Cases
The Zelicha et al 2025 study, led by UCLA health sciences professor Dr. Edward Livingston, exposes a massive disconnect between administrative data (billing codes) and clinical reality. Most large-scale medical research depends on databases like Medicare or the National Inpatient Survey, which use ICD-10 billing codes to identify patient diseases. The study, as summarized in this UCLA article, examined 1.36 million patient records and found that when researchers used billing codes to identify hernias, nearly two-thirds (66%) of the cases were misclassified.
The Solution: For a data lake to be useful for clinical research, it needs a tool that “visits” the clinical source to reconcile what was billed with what was actually proven. Without this “pre-lake” validation, two-thirds of the insights derived from that data could be fundamentally incorrect.
The Real Problem: We Discover Data Quality Issues Too Late
Today’s data pipelines follow a familiar pattern:
- Extract data from EHR systems
- Move it into a data lake
- Start cleaning it
- Realize it’s incomplete, invalid, or misclassified
- Spend months fixing it, or abandon the project
This is backwards.
By the time data scientists discover the problems, the damage is already done.
Worse, moving data around introduces:
- Security risks
- Governance challenges
- Duplication
- Loss of provenance
We need a way to assess data quality before it moves.
Enter FAIRlyz: A “First‑Responder” for EHR Data Quality
A new class of tools, data‑visiting quality‑control systems, offer a fundamentally different approach.
Instead of copying data into a new environment, tools like FAIRlyz:
- Visit the data where it lives
- Analyze quality, completeness, and structure in place
- Generate actionable reports for data custodians
- Flag invalid, missing, or misclassified fields early
- Help curate data before it enters a data lake or AI pipeline