The role of Persistent Identifiers (PIDs) – those enduring signposts in the digital landscape – is facing a fascinating challenge from the rise of Generative AI. At a recent meeting of the Research Data Alliance (RDA) PID Interest Group, experts gathered to debate whether AI is destined to make PIDs obsolete or, conversely, to amplify their importance. The discussions, which are set to continue at the upcoming RDA P25 event, sparked some compelling insights.
Traditionally, PID systems have been crucial for maintaining the link between an object (digital or physical) and its invariant name or identifier. This is vital for citation, referencing, and long-term data management. But what happens when AI enters the picture?
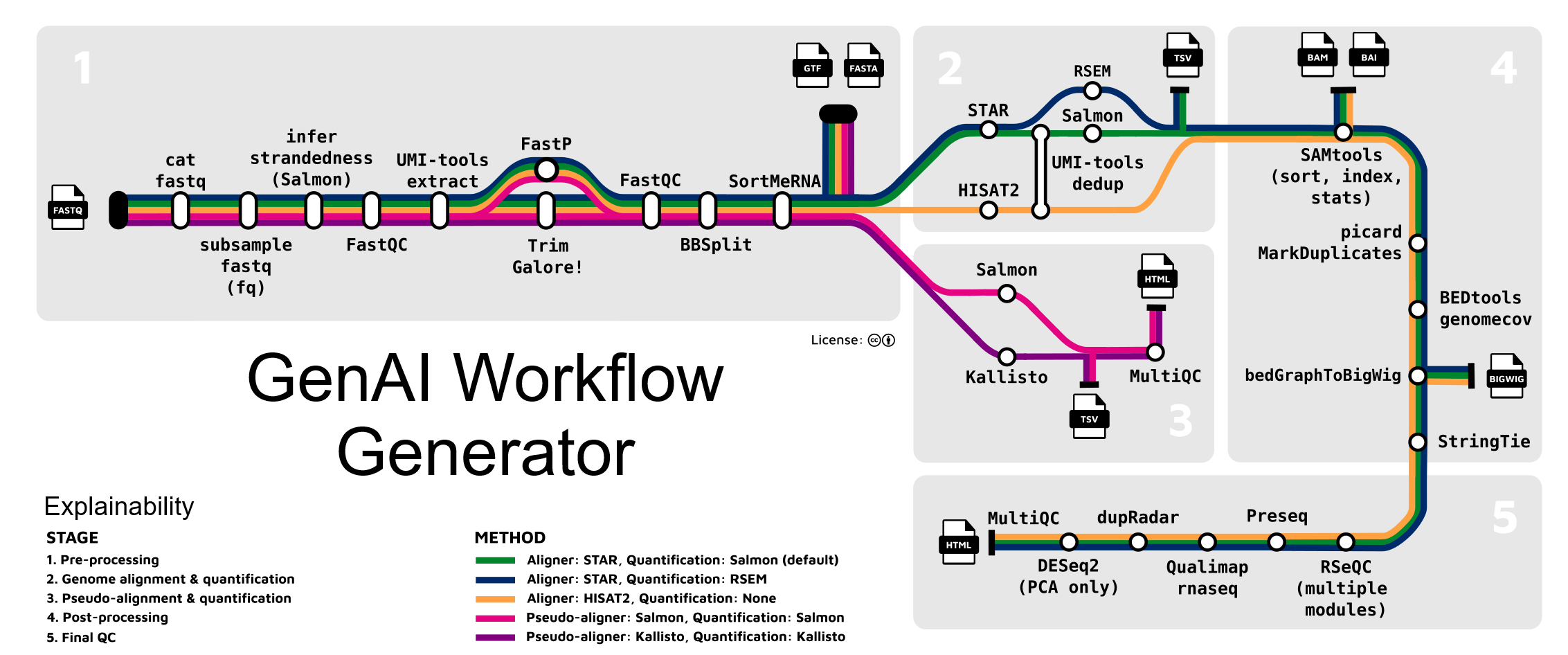
Rethinking Identifiers in the Age of Intelligent Workflow Automation
One of the most provocative ideas presented was that Generative AI’s ability to create and execute complex data processing workflows could fundamentally shift how we identify things. Imagine an AI system that, instead of relying on a static PID, or a static workflow, such as the ones used in bioinformatics (e.g. WDL or Nextflow workflows), dynamically constructs a workflow to analyze a dataset. This workflow might involve numerous steps, branching paths, and merging of tasks, all tailored to achieve a specific analytical outcome.
The argument goes that this very workflow, with its inherent logic and explainability, becomes the identifier. The precise sequence of operations, the tools used, and the decision points within the workflow provide a far richer and more descriptive “name” for the process than a simple string of characters in a PID. In this scenario, the PID’s traditional function of pointing to something is superseded by the workflow’s self-defining nature.
In the GenAI era of biomedical research, while quality metadata and raw data become paramount for training and validation, the traditional need for rigid PIDs for tracking specific datasets across different analyses might lessen. GenAI’s strength lies in its ability to dynamically learn from and rework the most current and optimized workflows to generate results and predictive models from this quality input. The focus shifts towards the reproducibility and explainability of the process and the resulting model, rather than solely on the immutable identification of every prior dataset instance, as workflows can evolve and influence outcomes.
AI’s Identity Crisis or Opportunity
The RDA PID session raised some profound questions.
Can AI truly “name” anything? AI’s ability to recognize and categorize objects (think facial recognition) is undeniable. But can it consistently assign a meaningful and enduring “name” that encapsulates all the relevant metadata?
Consistency and Similarity: If presented with the same or a very similar object or dataset, will AI generate the same workflow, or a slightly different but functionally equivalent one? The consistency of AI-generated “names” is critical.
Metadata Evolution: PID registries are rich in metadata, providing context and provenance. Can AI automatically generate this metadata, and more importantly, can it maintain its accuracy and relevance over time? Or will AI-driven systems evolve to the point where traditional metadata becomes less essential?
The Ongoing Debate
While some argue that AI could diminish the need for traditional PIDs and metadata, others believe it can revolutionize their creation and management. AI could automate the extraction of metadata from complex datasets, enhance its accuracy, and even predict future metadata needs.
The PID Interest Group discussions highlighted the complexity of this issue. We’re not simply asking if AI can replace PIDs; we’re exploring how AI is reshaping our understanding of what an identifier is and what it needs to do.
The debate is far from settled. As AI continues to evolve, the PID community must engage actively to ensure that our systems for identifying and managing information remain robust, reliable, and fit for the future. The upcoming P25/IDW event promises to be a crucial forum for further exploring these challenges and opportunities.
Who Should Care?
This discussion is relevant to anyone involved in the research data lifecycle: researchers, data managers, librarians, archivists, and organizations providing or using PID services. The future of data identification and management is being shaped by AI, and we all have a stake in ensuring its effectiveness.