In Part 1 of our series on the NIAID Data Ecosystem Discovery Portal, we discussed how the portal acts as a central hub for exploring Infectious and Immune-mediated Disease (IID) data. It accomplishes this by providing access to two key data sources: Resource Catalogs (curated scientific information collections) and Dataset Repositories (collections of specific experimental data). The portal utilizes various data providers like ImmPort, VEuPathDB, and NCBI to offer a comprehensive view of IID research, encompassing datasets, scientific publications, and associated information. This streamlined access empowers researchers to delve deeper into relevant IID data for their studies.
A Two-tiered Metadata System
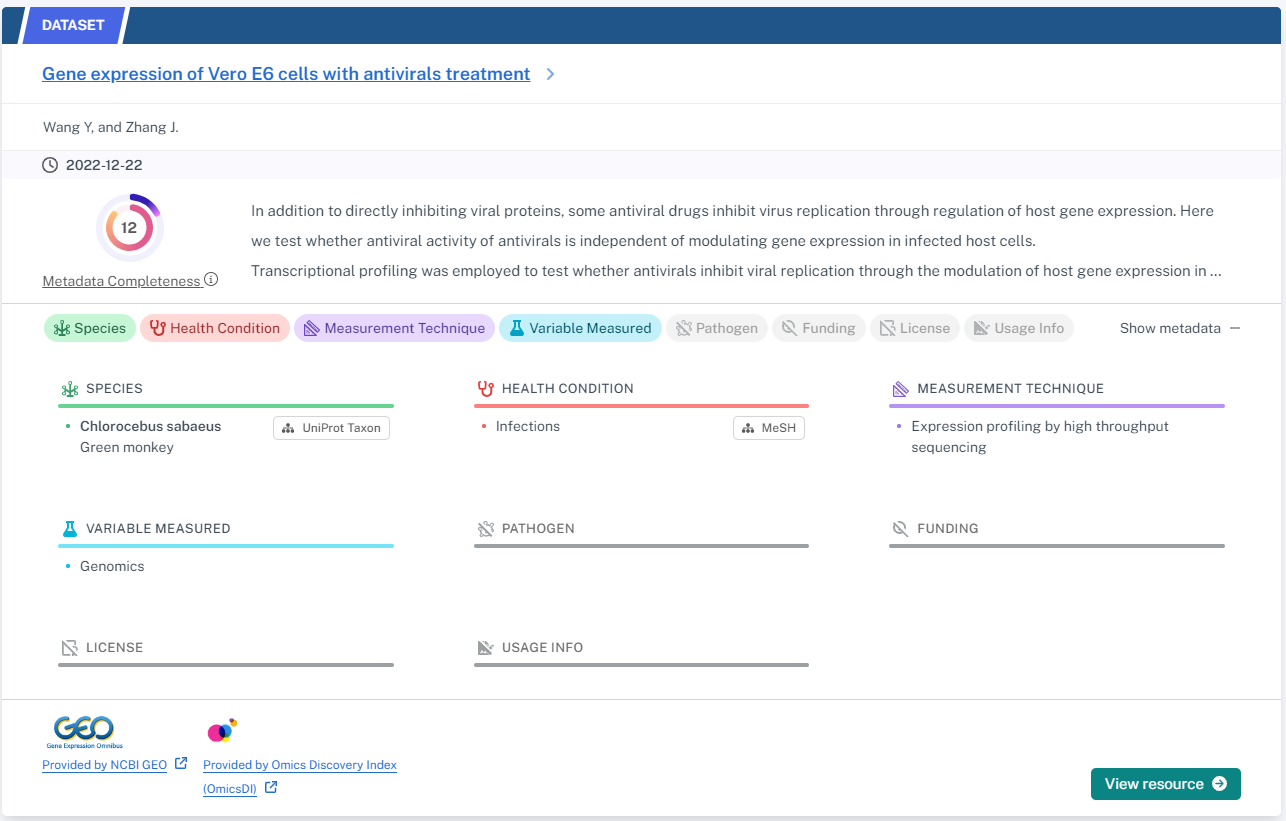
In Part 2 we look at the Metadata annotation feature. The metadata completeness score is a numerical indicator that measures how well data contributors have filled out the information (metadata) associated with a dataset. This score reflects whether essential details like funding sources, access conditions, or data collection dates are present. A high score signifies comprehensive metadata, making data easier to find and understand. Conversely, a low score suggests missing information, potentially hindering data interpretation and use. Users can leverage this score to judge if the metadata aligns with their needs before accessing or utilizing the data.
The NIAID Discovery Portal uses a two-tiered metadata system to ensure data understandability. The “Fundamental” tier sets a minimum standard for essential data details, while the “Recommended” tier offers additional, valuable information that data providers can include. This system acknowledges the importance of core information while allowing for richer data description through optional details. The completeness score reflects the inclusion of both tiers, with details on the breakdown available upon request.
The complete list of metadata elements and their definitions can be found in the Schema Registry of the Data Discovery Engine. The portal harvests metadata from dataset repository and harmonizes them to this schema to enable easy cross-platform dataset searching and filtering. The properties in the schema define an element and a list of elements, for example one may have one healthCondition to report or one may report more than one that make a list. Following FAIR principles, some properties, such as healthCondition, are of the type DefinedTerm and require describing several characteristics of the term including provenance as show in the example below.

Comparison to FAIRLYZ Metadata
When comparing how these platforms present metadata in search results, one distinction is that the NIAID portal shows the metadata information by expanding the results card via the “Show metadata” button. In FAIRLYZ the metadata is accessible by clicking on a study card which opens the study in a new page.
Similar to FAIRLYZ, the “Defined Terms” are shown with a link to their ontological definition, for example “Infections” has a link to the MeSH term for infections. In FAIRLYZ the definition is shown in an information tooltip with a link to the BioPortal ontology.
The FAIRLYZ UI like the NIAID Discovery Portal supports the definition of an element and a list of elements of the same type. Also similar to the NIAID Discovery Portal, FAIRLYZ uses a two-tiered metadata system with required and optional metadata elements.
The NIAID required or fundamental list of metadata elements is: name, author, includedInDataCatalog, funding, url, description, measurementTechnique, distribution, date (hierarchically derived from datePublished, dateModified, or dateCreated)
FAIRLYZ has different required metadata elements based on its use case of being a collaboration hub around data reuse. For example, the information is directly entered by a researcher or investigator, and thus the “author” information is not collected, and instead the “Data custodian” is recorded from the known profile of the user.
In FAIRLYZ, the collected funding information is the amount of funding obtained through a new FAIRLYZ study that was planned from conception in FAIRLYZ, or the funding obtained for a derivate study reusing data from a parent study that is registered in FAIRLYZ. NIAID collects information about all types of research funding.
The other required NIAID elements are also listed as required by FAIRLYZ, but FAIRLYZ separates study information from dataset information and collects information about the measurement techniques during data registration.
To ensure research context, FAIRLYZ requires additional elements at the study level: Study focus, Study Type, Data Type, Model System, Study Title, Study Description, Featured Image, Number of Subjects, Number of Samples, Start Date of Study. The FAIRLYZ pre-checks and QC process ensure numerous data elements meet quality standards, with specific requirements varying by data type (e.g., sequencing vs. phenotype data).
While both FAIRLYZ and the NIAID Discovery Portal provide access to scientific data, FAIRLYZ prioritizes collaboration through data sharing focused on data custodianship, contrasting with the Discovery Portal’s tiered, comprehensive metadata extracted from data repositories.