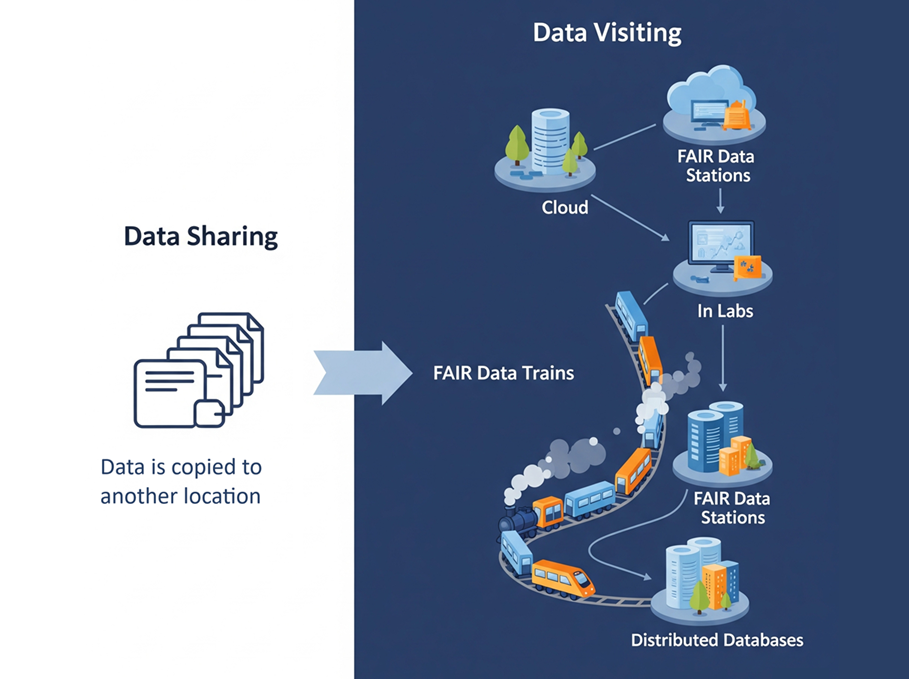
The FAIR Data Train is a data analysis approach that combines two key elements:
- FAIR Data Metadata Annotations, which ensure interoperability, and
- Data Visitation, which allows for remote analysis of the data.
As described in the LIFES Networking Meeting from December 2024:
The FAIR Data Train approach was introduced as a domain-agnostic system designed to enhance automated interoperability while adhering to FAIR principles. Key aspects include privacy-focused “data visiting”, foundational agreements for metadata handling, and core components like data stations and gateways. The environment promotes user-centric control, robust metadata, and simplified system integration, providing a scalable framework for FAIR data management. The separation of distributed, data holding stations and applications making (station controlled) use of the data is a key concept in the FAIR data train ecosystem.
Related Initiatives & Technologies
The Data Train concept is part of a broader movement toward privacy-preserving, federated data access.
Related Initiatives & Technologies
- Personal Health Train (PHT) – A European initiative that inspired the Data Train model, especially in health data.
- FAIR Data Train– Nodes that host data in a FAIR-compliant way and accept incoming Data Trains.
- Vantage6 – An open-source infrastructure for federated learning that supports the Data Train paradigm.
- FAIRlyz – A SaaS platform built on a data visitation model with in-place data QC and FAIR data stewardship.
A recent effort, SWARM Learning uses a federated system of AI/ML to visit data lakes at hospitals. In a 2021 study, published in Nature, Swarm Learning (SL) was introduced as a robust conceptual framework to enhance medical standards within a decentralized AI environment. Using a blood transcriptome dataset of over 12,000 patient samples, research demonstrated that AI models trained with Swarm Learning outperformed local models and matched centralized ones. This compelling evidence argues strongly for distributed solutions over highly centralized model development.
Although federated learning has successfully facilitated research with hospital EHR data, it leaves a crucial segment unaddressed: the countless scientific studies conducted globally that do not stem from or require access to hospital EHR data systems.
Given this significant unmet need, the LIFES organization, whose leadership pioneered the FAIR data principles, is now actively developing the FAIR Data Train architecture.
Introducing the FAIR Data Train Architecture
the FAIR Data Train architecture is an innovative approach that prioritizes interoperability across disparate datasets without requiring the replacement of existing data management systems, thereby extending FAIR principles to a much broader spectrum of scientific research.
The FAIR Data Train architecture is conceptualized around a robust train system analogy, featuring two core elements: Stations and Trains.
Stations act as secure data repositories, responsible for making data (or other digital objects) available without requiring their physical transfer. Critically, each Station provides comprehensive metadata about itself – describing its capabilities and policies – as well as detailed metadata about its contents (the data or digital objects it holds) enabling data discoverability and understanding.
Trains, in this analogy, represent analytical or processing algorithms. These “trains” securely “visit” Stations to process and analyze data in situ, meaning the computation happens where the data resides. This eliminates the need for sensitive data to leave its secure environment.
To facilitate efficient discovery within this network, a specialized Station Directory is also part of the FDT architecture. This Directory functions as a unique type of Station itself, indexing the metadata from all other Stations and providing powerful search capabilities. Researchers can consult the Station Directory to identify which Stations contain the specific data or digital objects relevant to their research, streamlining the process of finding and accessing appropriate datasets for analysis.
Difference between FAIRlyz Data Visitation and the FAIR Data Train
FAIRlyz, is a working implementation of a Data Visitation technology. It shares a foundational similarity with the FAIR Data Train architecture: both systems advocate for bringing computation to data rather than moving sensitive information. In the FAIRlyz’s model, the “Data Station” functions as any collection of research data, such as a data lake, securely housed within the data owner’s environment.
FAIRlyz differentiates itself by enabling secure in-place metadata annotation and quality control directly on these study datasets as a first step, effectively converting a data location into a “Train Station” based on quality control (QC) thresholds. During this process, FAIRlyz semi-automatically extracts rich metadata about the data and its content, leveraging advanced AI models like secure, private OpenAI APIs for enhanced data annotation. Crucially, only this comprehensive metadata, along with aggregated analysis results, is then securely transmitted to the central FAIRlyz Registry, which acts as the Station Directory, allowing other researchers to discover relevant studies and review findings without the sensitive raw data ever leaving its protected source.
Data visitation, as an innovative concept, is currently experiencing renewed attention and gaining significant traction. Researchers are guided in integrating this powerful approach throughout their entire research lifecycle using the FAIRlyz platform. This growing momentum is further exemplified by the upcoming LIFES conference on July 2, 2025. As highlighted on the conference website, the “Innovation Discussions” will specifically focus on the shift from traditional data sharing to ‘data visiting’ – a crucial step toward AI-readiness and equitable global data reuse.